C2 : Optimiser des applications
Compétence NON Clé
Création d’un système de logging
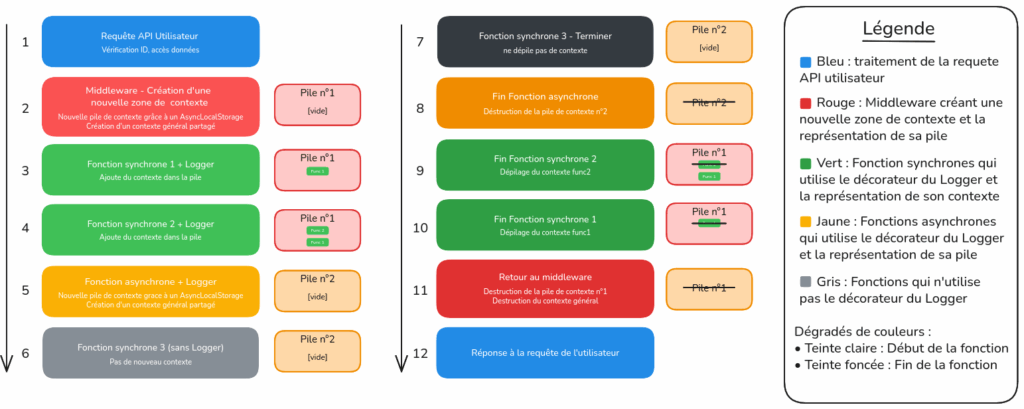
La figure 1 illustre une architecture avancée de logging pour Node.js/AdonisJS utilisant AsyncLocalStorage pour créer des contextes isolés par requête API. Le système fonctionne en créant une zone de contexte dédiée via un middleware lors de chaque requête utilisateur, puis maintient un système de pile hiérarchique qui trace l’enchaînement des fonctions synchrones et asynchrones. Les fonctions équipées du décorateur Logger enrichissent automatiquement leur pile de contexte (Pile n°1 pour les appels synchrones, Pile n°2 pour les appels asynchrones), tandis que les fonctions sans Logger s’exécutent de manière transparente. Le dépilage s’effectue automatiquement en ordre inverse lors du retour des fonctions, garantissant ainsi une isolation complète entre requêtes concurrentes, une traçabilité fine de l’exécution, et un nettoyage automatique des contextes pour optimiser les performances et faciliter le debugging en production.
Savoirs mobilisés
Ce projet a nécessité une compréhension approfondie des structures de données avancées et de leurs implications sur les performances dans un environnement concurrent. L’étude des mécanismes de stockage de contexte asynchrone a révélé l’importance de choisir les bonnes structures pour optimiser l’accès aux données tout en gérant l’isolation des contextes.
Les structures de pile (stack) et leur comportement LIFO (Last In, First Out) ont été étudiées pour les opérations synchrones, offrant une complexité temporelle O(1) pour les opérations push/pop.
L’analyse des problématiques de concurrence en JavaScript asynchrone a montré la nécessité d’isoler les contextes d’exécution. Contrairement aux opérations synchrones où une pile globale partagée est suffisante, les fonctions asynchrones peuvent s’exécuter en parallèle et créer des conditions de course (race conditions) si elles partagent la même pile de données. Chaque contexte asynchrone nécessite donc sa propre pile isolée pour éviter les interférences entre exécutions concurrentes.
AsyncLocalStorage est une API Node.js qui utilise une structure de données complexe pour maintenir un contexte local à travers des opérations asynchrones, similaire aux variables thread-local dans d’autres langages. Cette structure repose sur un système de chaînage de contextes qui peut créer une utilisation de la mémoire intensives si on veut en créer beaucoup.
Savoir-faire mis en œuvre
J’ai implémenté une structure de données hybride combinant AsyncLocalStorage avec une pile basée sur les tableaux JavaScript natifs, en tenant compte des contraintes de concurrence.
Pour les fonctions asynchrones, j’étais contraint d’utiliser AsyncLocalStorage afin d’éviter les problèmes de concurrence. Lorsque deux fonctions asynchrones s’exécutent simultanément, il est impossible d’utiliser une pile globale partagée car cela créesporait des conflits : les deux fonctions ne peuvent pas avoir deux têtes de pile distinctes sur la même structure. Par conséquent, l’algorithme crée une nouvelle pile isolée par fonction asynchrone via AsyncLocalStorage, garantissant l’isolation des contextes d’exécution.
L’algorithme utilise AsyncLocalStorage pour stocker et récupérer la pile de contexte propre à chaque contexte asynchrone, puis effectue les opérations de pile via push() et pop() sur le tableau JavaScript local. Cette approche résout le problème de concurrence tout en optimisant les performances : bien que l’accès initial à AsyncLocalStorage reste nécessaire pour l’isolation, le nombre d’accès est réduit en regroupant les opérations sur la pile locale.
La stratégie d’allocation mémoire crée une nouvelle pile par contexte asynchrone uniquement quand c’est nécessaire, évitant la multiplication excessive des structures tout en maintenant l’isolation requise pour la gestion de la concurrence.
La pile de contexte utilise directement l’API native des tableaux JavaScript car O(1) est l’une des meilleures performances à avoir dans son algorithme.
Sécurisation des clés API
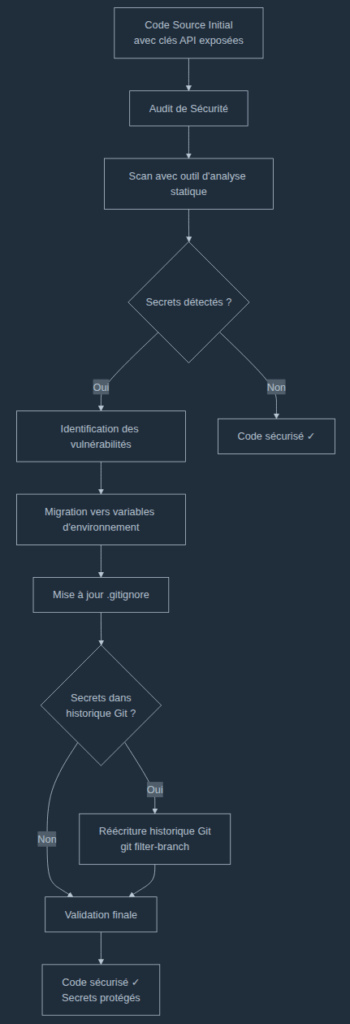
La figure 2 présente la méthodologie appliquée pour sécuriser les clés API exposées dans le code source. Le processus commence par un audit de sécurité suivi d’un scan automatisé pour détecter les secrets. Une fois les vulnérabilités identifiées, les clés API sont migrées vers des variables d’environnement et le fichier .gitignore est mis à jour pour éviter le versioning des secrets. Si l’historique Git contient des traces de ces clés, une réécriture complète de l’historique est effectuée via git filter-branch pour éliminer définitivement toute exposition. Le processus se termine par une validation finale garantissant que le code est entièrement sécurisé et que tous les secrets sont protégés.
Savoirs mobilisés
Ma formation en informatique m’a permis de comprendre les enjeux liés à l’exposition des secrets dans le code. J’ai mobilisé mes connaissances sur les différences fondamentales entre le frontend et le backend en matière de sécurité. En effet, le code frontend étant accessible côté client, toute clé API qui y serait présente devient potentiellement visible par les utilisateurs finaux. J’ai également appris que selon la portée et les permissions associées à une clé API, son exposition côté client peut être plus ou moins problématique, certaines clés avec un scope très limité pouvant parfois être acceptables côté client.
Par ailleurs, j’ai compris l’importance du principe de séparation entre la configuration sensible et le code applicatif. Les systèmes de versioning comme Git conservent l’historique complet des modifications, ce qui rend les secrets très difficiles à « effacer » complètement une fois qu’ils ont été commités. Cette compréhension m’a fait réaliser qu’une simple suppression des clés dans un nouveau commit ne suffit pas, car elles restent accessibles dans l’historique Git. Il est donc nécessaire de procéder à une réécriture de l’historique pour éliminer complètement toute trace des secrets exposés.
Savoir-faire mis en œuvre
Face à cette problématique, j’ai pris l’initiative d’utiliser un outil d’analyse statique que l’on peut exécuter depuis le terminal. Cet outil permet de scanner automatiquement le code source du projet pour détecter la présence de clés API, tokens d’authentification ou autres secrets potentiellement exposés. L’utilisation de cet outil s’est révélée très instructive car elle m’a permis d’identifier plusieurs endroits dans notre codebase où des informations sensibles étaient directement intégrées au code.
Suite à cette analyse, j’ai mis en œuvre les corrections nécessaires en migrant toutes les clés API identifiées vers des fichiers de configuration .env non versionnés. J’ai modifié le code pour qu’il utilise les variables d’environnement via process.env, et j’ai veillé à ce que le fichier .gitignore exclue bien ces fichiers sensibles du versioning. Pour les secrets qui avaient déjà été commités dans l’historique Git, j’ai procédé à une réécriture de l’historique en utilisant des outils comme git filter-branch pour supprimer définitivement toute trace de ces informations sensibles des logs Git. Cette étape était cruciale car elle garantit qu’aucune personne ayant accès au repository ne puisse récupérer les anciennes clés en consultant l’historique des commits.
Pour faciliter le travail des autres développeurs, j’ai également créé un fichier .env.example documentant les variables nécessaires sans exposer les valeurs réelles.
Amélioration des performances d’un site web


La figure 3 et 4 démontre l’impact concret des optimisations réalisées sur un site WordPress. L’audit GTmetrix révélait initialement un temps de chargement critique de 7,4 secondes pour le Largest Contentful Paint (LCP) (voir figure 3), indicateur clé de l’expérience utilisateur. Après analyse approfondie avec les DevTools Chrome et identification des images comme principale cause de lenteur, les optimisations ont permis de diviser ce temps par 4, passant à 1,7 secondes, et d’améliorer la note globale de D à B (voir figure 4).
Savoir mobilisé
Les Core Web Vitals sont trois métriques définies par Google pour mesurer l’expérience utilisateur réelle : l’Affichage du Plus Grand Contenu (LCP) qui mesure le temps d’affichage du plus gros élément visible avec un seuil recommandé inférieur à 2,5 secondes, le Délai de Première Interaction (FID) ou Temps de Blocage Total (TBT) qui évalue la réactivité aux interactions utilisateur avec des seuils respectifs inférieurs à 100ms et 200ms, et le Décalage Cumulé de Mise en Page (CLS) qui quantifie la stabilité visuelle pendant le chargement avec un seuil inférieur à 0,1. L’optimisation des performances web s’inscrit directement dans une démarche d’éco-conception numérique car chaque seconde de chargement supplémentaire génère une consommation énergétique accrue côté serveur (traitement PHP, requêtes base de données) et côté client (CPU, réseau), multipliée par le nombre d’utilisateurs. La réduction du LCP de 7,4s à 1,7s représente une diminution de la bande passante utilisée et de la charge processeur, s’appuyant sur les principes du Green IT où l’optimisation technique devient un levier environnemental concret : moins de transferts de données, utilisation plus efficace des ressources serveur, et réduction de l’empreinte carbone numérique globale.
Savoir-faire mis en œuvre
J’ai déployé une méthodologie d’audit systématique utilisant GTmetrix comme outil de mesure objective, permettant un suivi quantifiable avant/après intervention. La démarche comprenait l’analyse des Core Web Vitals pour identifier les goulots d’étranglement, puis l’implémentation de solutions techniques ciblées combinant optimisation des ressources (compression d’images avec maintien de la qualité visuelle, réduction du poids des assets) et optimisation serveur WordPress/PHP (audit et nettoyage de l’espace disque serveur, automatisation via tâche cron pour le nettoyage préventif du dossier /tmp). Cette approche holistique a permis d’atteindre des résultats concrets mesurables : passage de la note GTmetrix D à B, réduction de 77% du Largest Contentful Paint (7,4s → 1,7s), et maintien d’un Cumulative Layout Shift parfait (0), démontrant une capacité à mesurer, analyser et optimiser les performances de manière durable où chaque optimisation technique contribue directement à l’amélioration de l’expérience utilisateur et indirectement à la réduction de l’empreinte environnementale numérique.